8.18 Chapter 05
8.18 Chapter 05
결정트리
로지스틱 회귀로 와인 분류하기
- 로지스틱 회귀 모델을 사용했을 때, 그 계수와 가중치의 의미에 대해 설명하기 어렵다.
결정 트리
- 스무고개와 같은 결정 트리는 설명력이 높다.
- 데이터를 잘 나눌 수 있는 질문을 찾는다면 계속 질문을 추가해 분류 정확도를 높일 수 있다.
1
2
3
4
5
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
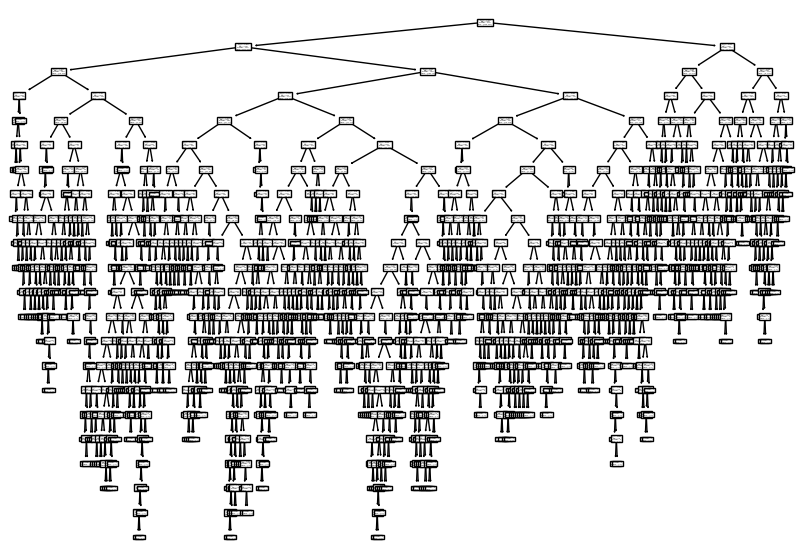
- 위 결정 트리의 맨 위의 노드를 루트 노드라고 부르고, 맨 아래 끝에 달린 노드를 리프 노드라고 합니다.
1
2
3
plt.figure(figsize=(10, 7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
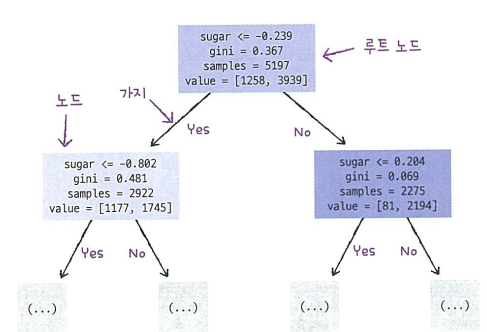
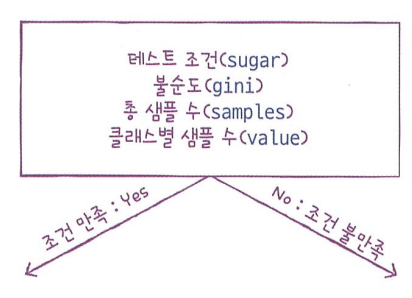
- 위 구조의 노드는 다음으로 이루어져 있습니다.
- max_depth 매개변수를 1로 주어 루트 노드를 제외하고 하나의 노드를 확장해서 그립니다.
filled 매개변수에서 클래스에 맞게 노드의 색을 칠할 수 있습니다.
- 결정트리에서 예측이란, 리프 노드에서 가장 많은 클래스가 예측 클래스가 됩니다.
gini 불순도
- gini는 지니 불순도를 의미합니다.
- 지니 불순도 = 1 - ((음성 클래스 비율)^2 +(양성 클래스 비율)^2)
- 결정 트리 모델은 부모 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장시킵니다.
- 이런 부모와 자식 노드 사이의 불순도 차이를 정보 이득이라고 부릅니다.
entropy 불순도
- 엔트로피 불순도도 노드의 클래스 비율을 사용하지만 지니 불순도처럼 제곱이 아니라 밑이 2인 로그를 사용해 곱합니다.
- -(음성 클래스 비율) * log(음성 클래스 비율) - (양성 클래스 비율) * log(양성 클래스 비율)
가지 치기
1
2
3
4
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
1
2
3
plt.figure(figsize=(20, 15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
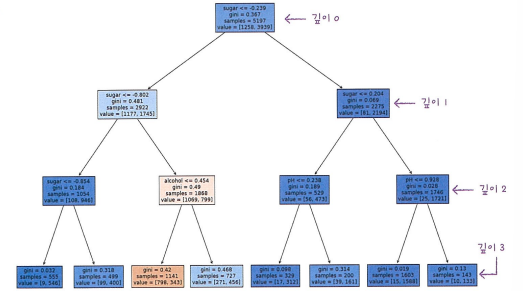
- 결정 트리는 표준화 전처리 과정이 필요하지 않습니다.
교차 검증과 그리드 서치
검증 세트
- 테스트 세트를 사용하지 않으면 모델이 과대적합인지 과소적합인지 판단하기가 어렵습니다.
- 테스트 세트를 사용하지 않고 이를 측정하는 간단한 방법으로 훈련 세트를 또 나누는데, 이 데이터를 검증 세트라고 부릅니다.
1
2
3
sub_input, val_input, sub_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42
)
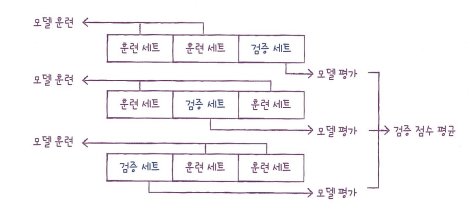
교차 검증
- 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복합니다.
- 그다음 이 점수를 평균하여 최종 검증 점수를 얻습니다.
- 3-폴드 교차 검증 말고도, 5-폴드나 10-폴드 교차 검증을 많이 사용합니다. 이러한 방식들은 데이터의 80~90%까지 훈련에 사용할 수 있습니다.
1
2
3
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
- cross_validate()는 훈련 세트를 섞어 폴드를 나누지 않습니다.
- 만약 교차 검증을 할 때 훈련 세트를 섞으려면 분할기를 지정해야 합니다.
- cross_validate() 함수는 기본적으로 회귀 모델일 경우 KFold 분할기를 사용하고, 분류 모델일 경우 타깃 클래스를 골고루 나누기 위해 StratifiedKFold를 사용합니다.
하이퍼파라미터 튜닝
- 최적의 매개변수를 찾기 위해 그리드 서치를 사용합니다.
1
2
3
4
5
6
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
- n_jobs 매개변수에서 병렬 실행에 사용할 CPU 코어 수를 지정하는 것이 좋습니다.
- 그리드 서치는 훈련이 끝나면 25개의 모델 중에서 검증 점수가 가장 높은 모델의 매개변수 조합으로 전체 훈련 세트에서 자동으로 다시 모델을 훈련합니다.
- 이 모델은 gs 객체의 best_estimator_ 속성에 저장되어 있습니다.
- 또한 그리드 서치로 찾은 최적의 매개변수는 best_params_ 속성에 저장되어 있습니다.
랜덤 서치
- 매개변수의 값이 수치일 때 범위나 간격을 미리 정하기 어려울 수 있습니다. 또 너무 많은 매개변수 조건이 있어 그리드 서치 수행 시간이 오래 걸릴 수 있습니다. 이럴 때 랜덤 서치를 사용하면 좋습니다.
- 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from scipy.stats import uniform, randint
rgen = randint(0, 10)
rgen.rvs(10)
np.unique(rgen.rvs(1000), return_counts=True)
ugen=uniform(0,1)
ugen.rvs(10)
np.unique(ugen.rvs(1000), return_counts=True)
params={
'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25),
}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(splitter='random', random_state=42),
params, n_iter=100, random_state=42)
gs.fit(train_input, train_target)
트리의 앙상블
정형 데이터와 비정형 데이터
- 정형 데이터: 어떤 구조로 되어 있는 데이터
비정형 데이터: 데이터베이스나 엑셀로 표현하기 어려운 데이터
- 정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘이 앙상블 학습입니다.
랜덤 포레스트
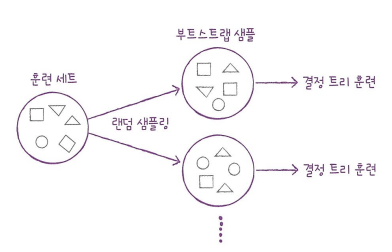
- 결정 트리를 랜덤하게 만들어 결정 트리의 숲을 만듭니다.
- 그리고 각 결정 트리의 예측을 사용해 최종 예측을 만듭니다.
- 데이터 세트에서 중복을 허용하여 데이터를 샘플링하는 방식을 부트스트랩 방식이라고 하고, 이런 방식으로 샘플링하여 분류한 데이터를 부트스트랩 샘플이라고 힙니다.
- 또한 각 노드를 분할할 때 전체 특성 개수의 제곱근만큼의 특성을 선택합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine-date')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42
)
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
- 랜덤 포레스트의 샘플링 과정에서, 부트스트랩 샘플에 포함되지 않고 남는 샘플을 OOB 샘플이라고 합니다.
- 이 남는 샘플을 사용해 부트스트랩 샘플로 훈련한 결정 트리를 평가할 수 있습니다.
엑스트라 트리
- 각 결정 트리를 만들 때 전체 훈련 세트를 사용하고, 노드를 분할할 때 가장 좋은 분할을 찾는 것이 아닌 무작위 분할을 합니다.
1
2
3
4
5
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores=cross_validate(et, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
그래이디언트 부스팅 -> 머신러닝 모델의 일종
- 깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식으로 앙상블하는 방법입니다.
- 깊이가 얕은 결정 트리를 사용하므로 과대적합에 강하고 일반적으로 높은 일반화 성능을 기대할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
scores=cross_validate(gb, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2,
random_state=42)
scores=cross_validate(gb, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
히스토그램 기반 그래이디언트 부스팅
먼저 입력 특성을 256개의 구간으로 나누고, 이 구간 중 하나를 떼어 놓고 누락된 값을 위해 사용합니다.
- 특성 중요도를 평가할 때, Permutation Importance를 사용한다.
- Permutation Importance란 특성 열들을 하나씩 섞으면서 정확도의 차이(감소율)를 특성마다 비교해보고, 제일 차이가 큰 특성을 중요도가 큰 특성이라고 결론내리는 방식이다.
1
2
3
4
5
6
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state=42)
scores = cross_validate(hgb, train_input, train_target,
return_train_score=True)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
- 에이다 부스트 방식 - 앙상블 학습의 또 다른 방식
This post is licensed under CC BY 4.0 by the author.