9.18 Chapter 01
9.18 Chapter 01
웹에서 주문 수를 분석하는 테크닉 10
데이터를 읽어 들이자
1
2
3
import pandas as pd
customer_master = pd.read_csv("customer_master.csv")
customer_master.head()
파이썬 라이브러리 판다스로 임포트를 한 뒤, read_csv를 사용해서 데이터 프레임형 변수에 저장합니다. 그 뒤 처음 5행을 표시하는 코드입니다.
이를 통해 어떤 데이터가 존재하고 각 데이터 간에 어떤 관계가 있는지와 같은 데이터의 큰 틀을 확인할 수 있습니다.
우선 데이터 전체를 파악하는 것이 중요하고, 그래서 되도록 상세하게 나와 있는 쪽에 맞추어 데이터를 가공하는 것이 중요합니다.
데이터를 결합(유니언)해 보자 - 세로 방향 결합
1
2
3
transaction_2 = pd.read_csv("transaction_2.csv")
transaction = pd.concat([transaction_1, transaction_2], ignore_index=True)
transaction.head()
- concat 함수를 통해 데이터를 행 방향으로 늘리어 세로로 결합합니다. 이를 통해 데이터의 개수에 변화가 있을 것입니다.
매출 데이터끼리 결합(조인)해 보자 - 가로 방향 결합
데이터를 조인할 때는 기준이 되는 데이터를 정확하게 결정하고, 어떤 칼럼을 키로 조인할 지를 생각합니다.
이를 위해, 부족한(추가하고 싶은) 데이터 칼럼이 무엇인가와 공통되는 데이터 칼럼은 무엇인가를 생각합니다.
1
2
join_data = pd.merge(transaction_detail, transaction[["transaction_id", "payment_date", "customer_id"]], on="transaction_id", how="left")
join_data.head()
- merge함수를 통해 기준은 transaction_detail, 조인키는 결합할 transaction 데이터의 필요한 칼럼 transaction_id 입니다. 이 키를 바탕으로 transaction 데이터의 칼럼들을 추가합니다.
마스터데이터를 결합(조인)해 보자
1
2
3
join_data = pd.merge(join_data, customer_master, on="customer_id", how="left")
join_data = pd.merge(join_data, item_master, on="item_id", how="left")
join_data.head()
필요한 데이터 칼럼을 만들자
1
2
join_data["price"] = join_data["quantity"] * join_data["item_price"]
join_data[["quantity", "item_price", "price"]].head()
- 데이터를 결합할 때는 신중히 개수를 확인해야 합니다. 되도록 검산이 가능한 데이터 칼럼을 찾고 계산합니다.
데이터를 검산하자
1
join_data["price"].sum() == transaction["price"].sum()
- 간단히 각각의 price 총합을 확인해 데이터를 검산합니다.
각종 통계량을 파악하자
- 데이터 분석을 진행할 때는 먼저 크게 두 가지의 숫자를 파악해야 합니다.
- 결손치의 개수
- 전체를 파악할 수 있는 숫자감
1
2
3
4
# 결손치의 개수를 파악
join_data.isnull().sum()
# 전체를 파악할 수 있는 숫자감을 확인
join_data.describe()
월별로 데이터를 집계해 보자
- 전체적으로 매출이 늘어나고 있는지 줄어들고 있는지를 파악하는 것이 분석의 첫걸음이라고 할 수 있습니다.
1
join_data.groupby("payment_month").sum(numeric_only=True)["price"]
월별, 상품별로 데이터를 집계해 보자
1
2
3
join_data.groupby(["payment_month", "item_name"]).sum(numeric_only=True)[["price", "quantity"]]
pd.pivot_table(join_data, index="item_name", columns="payment_month", values=["price", "quantity"], aggfunc="sum")
- pivot_table을 통해 집계할 때, 행에는 상품명, 칼럼에는 월이 오게 index와 columns로 지정합니다. values에는 집계하고 싶은 칼럼(price, quantity), aggfunc에는 집계 방법을 지정합니다.
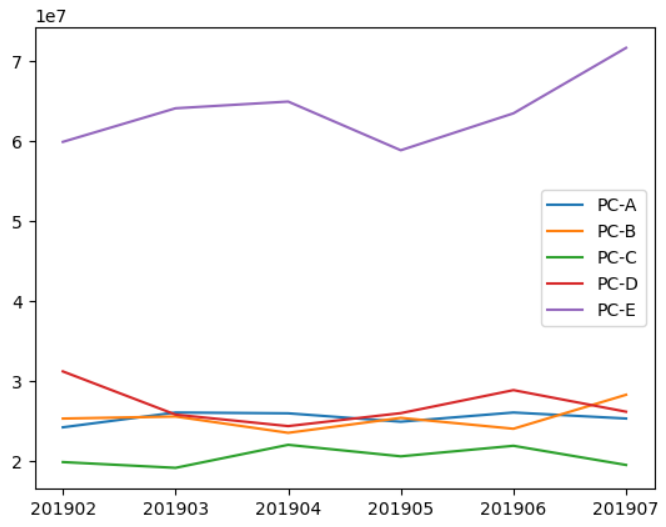
상품별 매출 추이를 가시화해 보자
1
2
3
4
5
6
7
8
9
10
11
12
graph_data = pd.pivot_table(join_data, index="payment_month", columns="item_name",
values="price", aggfunc="sum")
graph_data.head()
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(list(graph_data.index), graph_data["PC-A"], label="PC-A")
plt.plot(list(graph_data.index), graph_data["PC-B"], label="PC-B")
plt.plot(list(graph_data.index), graph_data["PC-C"], label="PC-C")
plt.plot(list(graph_data.index), graph_data["PC-D"], label="PC-D")
plt.plot(list(graph_data.index), graph_data["PC-E"], label="PC-E")
plt.legend()
This post is licensed under CC BY 4.0 by the author.