11.11 Chapter 13
11.11 Chapter 13
- 교재:13.10 단원
선형 판별분석과 이차 판별분석(분류 모델)
- 판별분석은 로지스틱 회귀분석처럼 질적 철도로 이루어진 종속변수를 분류할 때 쓰이는 분석 기법이다.
- 성능 면에서 로지스틱 회귀분석보다 우수한 것으로 알려져 있으며, 30% 적은 데이터로도 로지스틱 회귀분석과 유사한 성능을 낼 수 있다.
- 범주가 두 개일 경우 일반 판별분석 혹은 두 집단 판별분석이라고 부르고, 세 개 이상일 경우 다중 판별분석이라 한다.
- 범주를 구분하는 결정경계선을 산출하는 방식에 따라 선형 판별 분석과 이차 판별 분석으로 구분한다.
선형 판별 분석
- 종속변수의 범주 간 분별 정보를 최대한 유지시키면서 차원을 축소시키는 방식으로 데이터의 오분류율이 최소가 되는 축을 찾는다.
집단 내 분산에 비해 집단 간 분산의 차이를 최대화하는 독립변수의 함수를 찾는 것이다.
선형 판별 함수 수식은 아래와 같다.
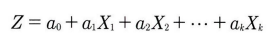
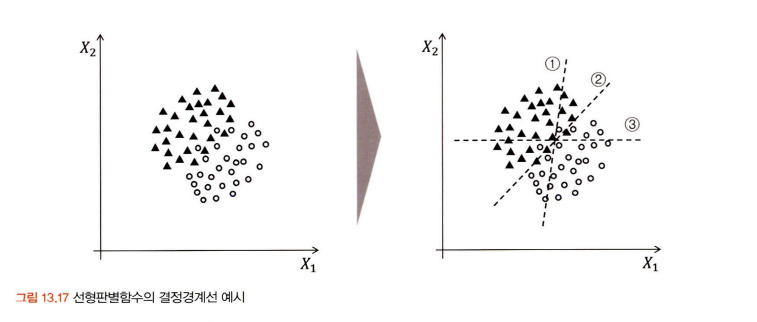
- 아래의 그림은 최적의 분류선을 찾는 과정이고 2번 직선이 제일 적합하다고 볼 수 있다.
이차 판별 분석
- 선형 판별 분석이 공분산 구조가 많이 다른 범주의 데이터를 잘 분류하지 못한다는 단점을 보완한 방법이다.
- 비선형 분류가 가능하다는 장점이 있지만, 독립변수가 많을 경우 추정해야 하는 모수가 많아져서 선형 판별 분석에 비해 연산량이 크다는 단점이 있다.
서포트 벡터머신(분류모델)
- 판별 분석과 같이 범주를 나눠줄 수 있는 최적의 구분선을 찾아내어 관측치의 범주를 예측해주는 역사 깊은 모델이다.
- SVM에서 가장 중요한 결정경계선을 만들어내는 원리를 중심으로 살펴보면 다음과 같다.
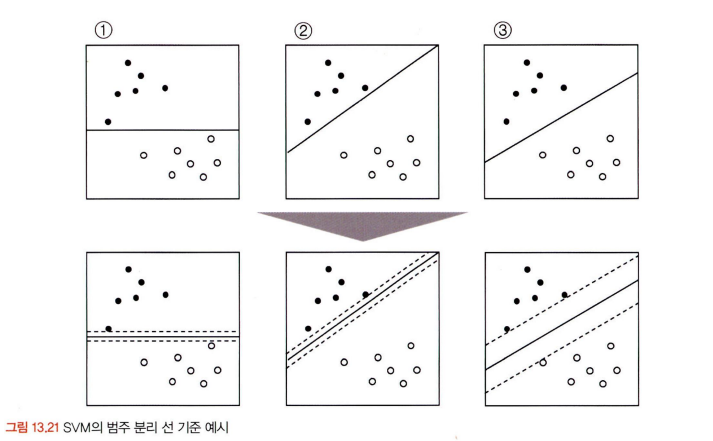
- 위의 그림에서 마진을 최대화하도록 결정경계선을 선택한다.
- 또한, 기계학습에서 거리를 통해 분류나 회귀 모델을 만들 때는 반드시 데이터 정규화나 표준화를 해줘야 한다.
- 이를 통해 데이터를 정규화시킨 후 마진값이 최대가 되도록 SVM의 결정경계선을 찾아주면 다음과 같다.
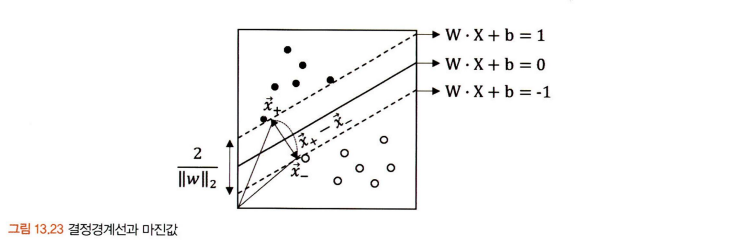
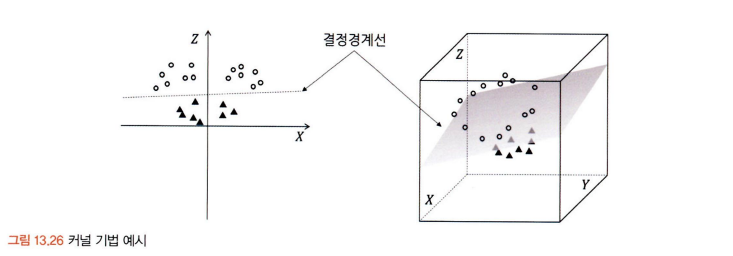
- 위와 같은 방법으로 결정경계선을 만들기 힘든 경우, 커널 기법이라는 기존의 데이터를 고차원 공간으로 확장하여 새로운 결정경계선을 만드는 방법을 사용한다.
시계열 분석(예측모델)
회귀 기반 시계열 분석
- 회귀 기반 모델은 예측하고자 하는 시점 t의 값이 종속변수가 된다.
- 그리고 t 시점에 해당하는 요소들이 독립변수가 된다.
- 시계열이 비선형적인 경우에는 일반 선형 회귀식으로 표현하는 것은 어렵고, 그렇기에 비선형 추세의 경우 다항회귀를 하여 모델 적합성을 향상시킨다.
회귀 모형 기반의 시계열 분석의 장점 중 하나는 외부 요소를 변수로 추가해 주는 것이 용이하다는 것이다. 이를 통해 부정기적인 노이즈 요소를 최소화할 수 있다.
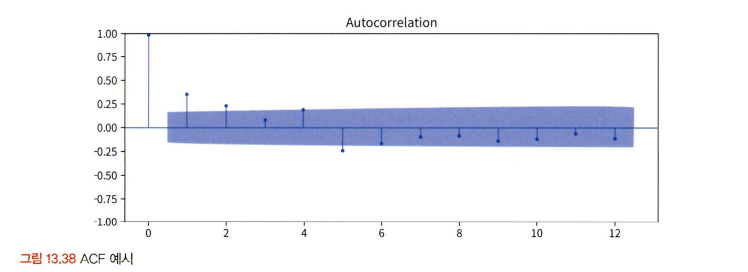
- 아래는 자기상관함수 ACF를 이용해 시계열 데이터의 주기성을 수치적으로 확인하고, 특정 시차가 어떠한 영향을 주는지 알 수 있다.
ARIMA 모델
- 이동평균을 누적한 자기회귀를 활용하여 시계열 분석을 하는 것이다.
- ARMA(p, q) 모델 자체의 불안정성을 제거하는 기법을 결합한 모델이 ARIMA 모델이다.
- ARIMA(p, d, q) 모델은 시계열 데이터를 d회 차분하고 p만큼의 과거 값들과 q만큼의 과거 오차 값들을 통해 수치를 예측하고 차분한 값을 다시 원래의 값으로 환산하여 최종 예측값을 산출한다.
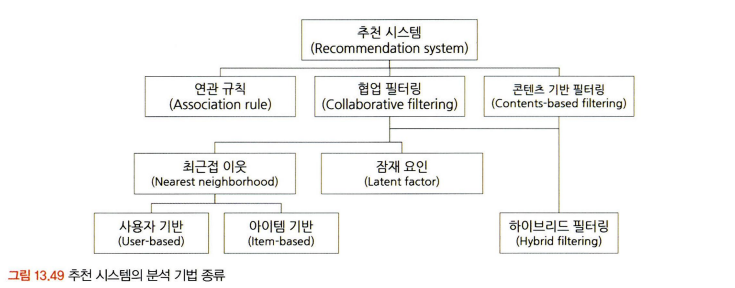
연관규칙과 협업 필터링(추천 모델)
- 전통적 추천의 유형은 다음의 세 가지가 있다.
- Editorial and hand curated
- Simple aggregates
- Tailored to individual users
연관 규칙
- A라는 제품을 구매한 사람은 B라는 제품도 구매할 확률이 높다는 결과를 이끌어 내는 모델이다.
- 대표적인 알고리즘으로 다음이 있다.
- Apriori
- FP-Growth
- DHP
- 품목 간의 연관 관계 계산은 각 품목 조합의 출현 빈도를 이용한다.
- 다음의 세 가지 핵심 지표를 통해 품목 조합 간의 연관성의 수준을 도출한다.
- 지지도: 전체 구매 횟수 중에서 해당 아이템 혹은 조합의 구매가 얼마나 발생하는지
- 신뢰도: 아이템 A가 판매됐을 때 B 아이템도 함께 포함되는 조건부 확률
- 향상도: 아이템 A의 판매 중 아이템 B가 포함된 비율이, 전체 거래 중 아이템 B가 판매된 비율보다 얼마나 증가했는지를 나타내는 지표
콘텐츠 기반 필터링과 협업 필터링
- 콘텐츠 기반 필터링
- 아이템의 속성을 활용하여 추천하는 방법이다.
- 아이템의 메타 정보를 활용한다.
- 정형화된 데이터를 통해 기존의 선호와 유사한 아이템을 추천할 수 있다는 장점이 있다.
- 하지만 모든 제품에 대한 메타 정보를 입력해야 작동하기 때문에 아이템이 많아질 경우 관리가 힘들어진다.
- 협업 필터링 모델
- 유사한 성향을 가진 사람들을 찾아내어 그 사람들이 선호하는 아이템을 추천해 주는 방식으로 수행된다.
- 이는 피어슨 유사도나 코사인 유사도를 통해 구할 수 있다.
인공 신경망(CNN, RNN, LSTM)
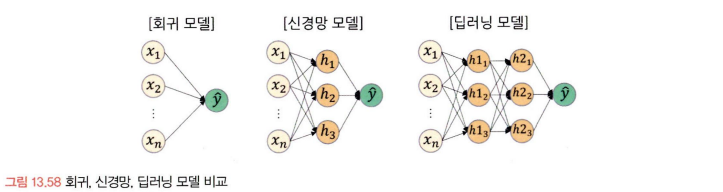
- 기본적인 신경망 구조는 입력층, 은닉층, 그리고 출력층으로 되어 있다. 또한 이러한 신경망 모델을 블랙박스 모형이라고 부른다.
- 입력층: 독립변수의 값들을 입력하는 역할
- 은닉층: 입력층에서 들어온 값들을 합산하여 보관하고, 노드들을 연결하는 층 사이에는 가중치들이 있다.
CNN
- 합성곱 신경망으로 사람의 시신경 구조를 모방한 구조로써 데이터의 특징을 추출하여 패턴을 파악한다.
RNN과 LSTM
- RNN
- 자연어처리에서 많이 쓰이는 순환신경망이다.
- 알고리즘 내부에 순환구조가 들어있다.
- LSTM
- 기존 RNN과 유사한 구조를 가지고 있지만 셀 스테이트라는 요소를 가지고 있다.
- 셀 스테이트는 가중치를 계속 기억할 것인지 말 것인지를 결정해주는 역할을 한다.
- 이를 통해 가중치가 기억되면, 거리가 먼 과거의 인풋이라 해도 가중치가 그대로 적용된다.
This post is licensed under CC BY 4.0 by the author.