11.05 Chapter 03
11.05 Chapter 03
데이터 분석하기
통계 기반 분석 방법론
분석 모델 개요
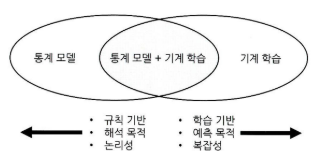
- 데이터 분석의 방법론은 크게 통계학에 기반한 통계 모델과 인공지능에서 파생된 기계 학습으로 나뉜다.
- 통계 모델: 모형과 해석을 중요하게 생각하며, 오차와 불확정성을 강조한다.
- 기계 학습: 대용량 데이터를 활용하여 예측의 정확도를 높이는 것을 중요하게 생각한다.
- 기계 학습의 경우, 종속 변수의 유무에 따라 혹은 독립변수와 종속변수의 속성(질적 혹은 양적)에 따라 방법론이 결정된다.
- 지도학습은 입력에 대한 정답이 주어져서 출력된 결괏값과 정답 사이의 오차가 줄어들도록 학습과 모델 수정을 반복한다.
- 자율학습으로도 불리는 비지도 학습은 별도의 정답이 없이 변수 간의 패턴을 파악하거나 데이터를 군집화하는 방법이다.
- 대표적으로 차원 축소, 군집 분석, 연관 규칙이 있다.
- 차원 축소: 지도학습을 할 때 학습 성능을 높이기 위한 전처리 방법으로 사용
- 군집 분석: 정답지없이 유사한 관측치들끼리 군집으로 분류하는 기법
- 연관 규칙: 각 소비자의 구매 리스트를 통해 제품 간의 연관성을 수치화하여, 소비자가 앞으로 구매할 가능성이 높은 제품을 추천하도록 할 수 있는 방법론
- 강화학습: 동물이 시행착오를 통해 학습하는 과정을 기본 컨셉으로 한 방법 중 하나
주성분 분석(PCA)
- 주성분 분석은 여러 개의 독립변수들을 잘 설명해 줄 수 있는 주된 성분을 추출하는 기법이다.
- 사용되는 변수들이 모두 등간 척도나 비율척도로 측정한 양적변수여야 하고, 관측치들이 서로 독립적이고 정규분포를 이루고 있어야 한다.
- 차원을 감소하는 방법은 크게 두 가지로 구분할 수 있다.
- 첫째는 변수 선택을 통해 비교적 불필요하거나 유의성이 낮은 변수를 제거하는 방법
- 둘째는 변수들의 잠재적인 성분을 추출하여 차원을 줄이는 방법
- 일반적으로는 제1주성분, 제2주성분만으로 대부분의 설명력이 포함되기 때문에 두 개의 주성분만 선정한다.
- 전체 분산 중에서 해당 주성분이 갖고 있는 분산이 곧 설명력이라 할 수 있다.
공통요인분석(CFA)
- 요인분석: 주어진 데이터의 요인을 분석한다는 큰 개념
요인분석을 하기 위해 전체 분산을 토대로 요인을 추출하는 PCA를 사용하거나, 공통분산만을 토대로 요인을 추출하는 CFA를 선택할 수 있다.
- 큰 개념인 요인분석은 목적에 따라 탐색적 요인분석과 확인적 요인분석으로 구분할 수 있다.
- 탐색적 요인분석(EFA)은 변수와 요인 간의 관계가 사전에 정립되지 않거나 체계화되지 않은 상태에서 변수 간의 관계를 알아보기 위해 사용한다.
확인적 요인분석(CFA)은 이미 변수들의 속성을 예상하고 있는 상태에서 실제로 구조가 그러한지 확인하기 위한 목적으로 쓰인다.
- 공통요인분석은 전체 독립변수를 축약하는 것으로, 상관성이 높은 변수들을 묶어 잠재된 몇 개의 변수를 찾는 과정이다.
PCA나 CFA와 같은 요인분석을 하기 위해서는 우선 독립변수들 간의 상관성이 요인분석에 적합한지 검증을 해야 하는데, 이를 확인하기 위한 방법으로 바틀렛 테스트와 KMO 검정을 수행한다.
- 적합성을 검증한 이후, 요인분석을 통해 생성되는 주성분 변수들의 고유치를 확인하여 요인의 개수를 결정한다.
다중공선성 해결과 섀플리 밸류 분석
- 다중공선성이란 독립변수들 간의 상관관계가 높은 현상을 말한다.
회귀 분석 모델에서 다중공선성이 있는 경우, 회귀계수 추정치의 해석이 어려워지고, 예측 성능이 과장되어 나올 수 있기 때문에 모델의 유의성을 판단하기 어려워진다.
- 다중공선성을 해결하기 위한 방법은 다음과 같다.
- VIF값이 높으면서 종속변수와의 상관성이 낮은 변수 제거
- 표본 관측치를 추가적으로 확보
- 로그, 표준화 등을 통한 변수 가공
- 주성분분석을 통한 변수 축약
- 변수 선택 알고리즘을 활용하여 적정 변수 자동 선정
- 이외에도 각 독립변수가 종속변수의 설명력에 기여하는 순수한 수치를 계산하는 방법인 섀플리 밸류 분석 방법도 존재한다.
데이터 마사지와 블라인드 분석
데이터 마사지
- 데이터 분석 결과가 예상하거나 의도한 방향과 다를 때 데이터의 배열을 수정하거나 관점을 바꾸는 등 동일한 데이터라도 해석이 달라질 수 있도록 유도하는 것이다.
- 데이터 왜곡에 당하거나 직접 하지 않기 위해 잘 이해하고 있어야 한다.
블라인드 분석
- 데이터 마사지에 의한 왜곡을 방지하기 위해 사용하는 방법
- 인지적 편향 혹은 확증 편향에 의한 오류를 최소화하기 위한 방법
Z-test와 T-test 혹은 ANOVA
- 집단 내 혹은 집단 간의 평균값 차이가 통계적으로 유의미한 것인지 알아내는 방법
- Z-test와 T-test는 분석하고자 하는 변수가 양적 변수이며, 정규 분포이며, 등분산이라는 조건이 충족되어야 한다.

- T-test에서 검정 통계량 t값이 임계치보다 크지 않으면 대립가설을 기각하고 귀무가설을 채택한다.
ANOVA(Analysis of Variance)
- 세 집단 이상의 평균을 검정할 때 사용
- 이 역시 결국 집단의 종류(독립변수)가 평균 값의 차이 여부(종속변수)에 미치는 영향을 검정하는 것이다.
- 독립변수인 요인의 수에 따라서 one-way ANOVA, two-way ANOVA, N-way ANOVA와 같이 다양하게 불린다.
- 큰 개념으로 집단 간 평균의 분산을 집단 내 분산으로 나눈 값이 유의도 임계치를 초과하는가에 따라 집단 간 평균 차이를 검정하는 것이다.
- 임계치를 초과하는 경우, 집단 간 평균에는 통계적으로 유의미한 차이가 있다고 본다.
카이제곱 검정(교차분석)
- 명목 혹은 서열척도와 같은 범주형 변수들 간의 연관성을 분석하기 위해 결합분포를 활용하는 방법이다.
- 변수들간의 범주를 동시에 교차하는 교차표를 만들어 각각의 빈도와 비율을 통해 변수 상호 간의 독립성과 관련성을 분석하는 것이다.
- 명목척도로 이루어진 두 개의 변수를 교차표로 표현 - 기대빈도 계산 - 실제 관측빈도와 기대빈도와의 차이를 통해 상호독립성과 관련성을 분석
- 기대빈도를 이용하여 검정통계량을 산출하고 이를 유의수준에 따라 결정된 임계치와 비교하여 유의수준보다 낮으면 상관성이 없다는 귀무가설을 채택한다.
머신러닝 분석 방법론
회귀분석의 기원과 원리
- 회귀분석은 해당 객체가 소속된 집단의 X(독립변수) 평균값을 통해 Y(종속변수) 값을 예측하는 것이 기본적인 원리다.
- 즉, 종속변수의 값에 영향을 주는 독립변수들의 조건을 고려하여 구한 평균값이다.
- 절편, 기울기, 오차항으로 이루어진다.
- 예측치와 관측치들 간의 수직 거리(오차)의 제곱합을 최소로 하는 직선이 회귀선이 된다.(최소제곱추정법)
- 회귀분석은 독립변수 간에 상관관계가 없어야 하기 때문에 다중 회귀 분석을 할 때는 다중공선성 검사를 해야 한다.
다항 회귀
- 독립변수와 종속변수의 관계가 비선형 관계일 때 변수에 각 특성의 제곱을 추가하여 회귀선을 비선형으로 변환하는 모델이다.
- T-Value는 노이즈 대비 시그널의 강도로, 독립변수와 종속변수 간에 선형관계가 얼마나 강한지를 나타내기 때문에 그 값이 커야 한다.
- 유의도를 나타내는 P-Value는 T-Value와 관측치 수에 의해 결정되는 값이다.
- 변수별 유의도와 공선성 통계량을 통해 모델에 최종적으로 사용할 변수를 선택할 수 있다.
- 전진 선택법: 절편만 있는 모델에서 시작하여 유의미한 독립변수 순으로 변수를 차례로 하나씩 추가하는 방법
- 후진 제거법: 모든 독립변수가 포함된 상태에서 시작하여 유의미하지 않은 순으로 설명변수를 하나씩 제거하는 방법
- 단계적 선택법: 처음에는 전진선택법과 같이 변수를 하나씩 추가하기 시작하면서, 선택된 변수가 3개 이상이 되면 변수 추가와 제거를 번갈아 가며 수행한다.
- 모델의 잔차(residual)란 관측값과 모델이 예측한 값의 차이를 말한다.
- 이 외에도 Elastic Net도 있다.
Rigid와 Lasso 그리고 Elastic Net
- 모델에 최종적으로 사용할 유의미한 변수를 선택하는 방법론
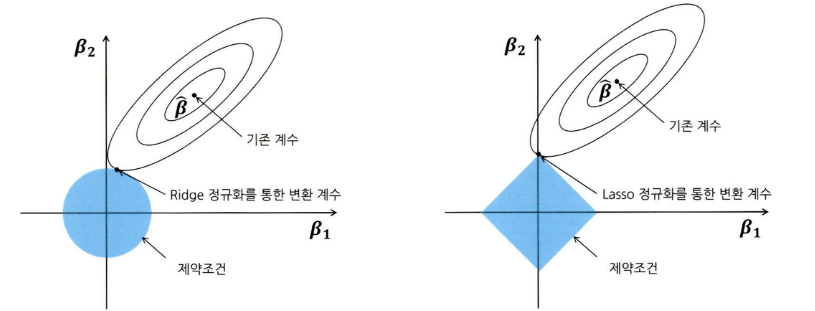
- Rigid
- 전체 변수를 모두 유지하면서 각 변수의 계수 크기를 조정한다.
- 종속변수 예측에 영향을 거의 미치지 않는 변수는 0에 가까운 가중치를 주게 하여 독립변수들의 영향력을 조정해 주는 것이다.(계수 정규화)
- L2-norm이라고도 하며 매개변수의 값을 조정하여 정규화 수준을 조정한다.
- Lasso
- 중요한 몇 개의 변수만 선택하고 나머지 변수들은 계수를 0으로 주어 변수의 영향력을 아예 없앤다는 점에서 Rigid와 차이가 있다.
- L1-norm이라고도 하며 Rigid처럼 매개변수 값을 통해 정규화의 강도를 조정한다.
- Elastic Net
- Ridge와 Lasso의 최적화 지점이 다르기 때문에 두 정규화 항을 결합하여 절충한 모델이다.
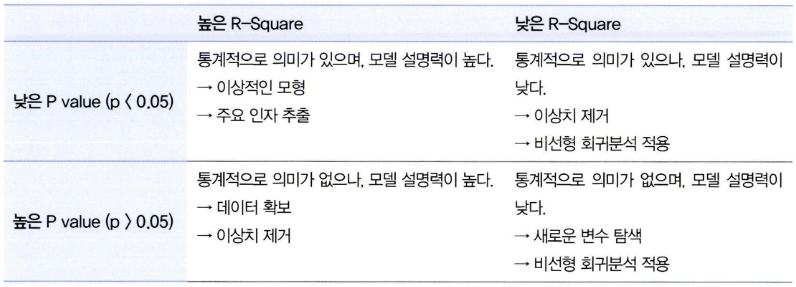
- 이를 통해 p-value와 R-square 값에 따른 모델 튜닝 전략을 살펴보면 다음과 같다.
This post is licensed under CC BY 4.0 by the author.